索引组织表
在InnoDB存储索引中,表时根据主键顺序组织存放的,这种存储方式的表称为索引组织表。
在InnoDB存储引擎表中,每张表都有个主键,如果在创建表时没有显式地定义主键,则会按照如下方式创建主键:
- 判断表中是否有非空的唯一索引,如果有该列为主键;
- 表中没有非空的唯一索引,InnoDB引擎自动创建一个6字节大小的指针;
当表中有多个非空唯一索引时,InnoDB存储引擎将选择建表时第一个定义的非空唯一索引为主键(根据定义的索引顺序,而不是建表时列的顺序)。
InnoDB逻辑存储结构
表空间
表空间是InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空间中。
表空间由段(Segment)、区(extent)、页(Page)组成。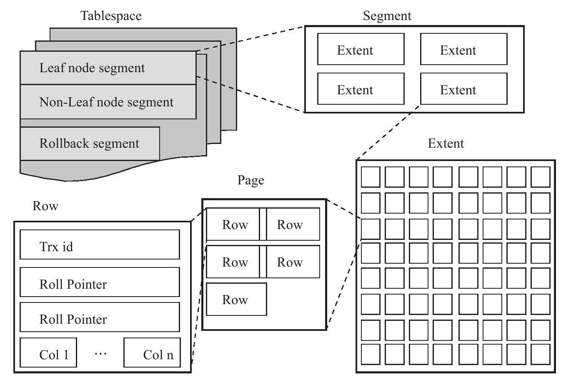
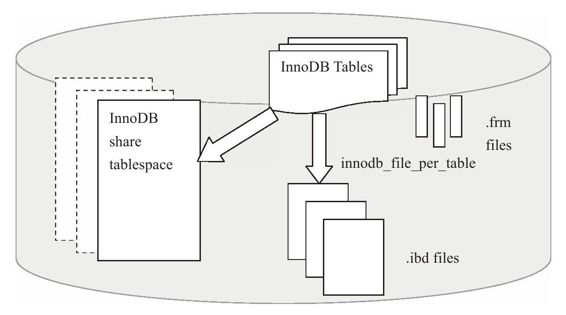
在默认情况下,InnoDB存储引擎有一个共享表空间ibdata1,所有的数据都存放在这个表空间内。
如果配置了innodb_file_per_table,则每张表内的数据可以单独存放在一个表空间中。此时每张表的表空间存放的只是数据、索引和插入缓冲的BitMap页,其他类的数据如回滚(undo)、插入缓冲索引页、系统事务信息、二次写缓冲等还是存放在原来的共享表空间。
段
表空间是由各个段组成的,包含数据段、索引段、回滚段等。
数据段就是B+树的叶子节点,索引段就是B+树的非叶子结点。
回滚段???
在InnoDB存储引擎中,对段的管理都是由引擎自身完成的,DBA不能对其进行控制。
区
区是由连续的页组成的空间,在任何情况下每个区的大小都是1MB。为了保证区中页的连续行,InnoDB引擎每次从磁盘申请4~5个区。默认情况下InnoDB存储引擎页的大小为16K,一个区中存放64个连续的页。
页
页是InnoDB磁盘管理的最小单位,在InnoDB存储引擎中,默认每个页的大小为16KB。
可以通过参数 innodb_page_size 来设置页的大小为4K、8K、16K。
如果设置完成,则所有表中的页大小都变成innodb_page_size,不可用对其再次进行修改。除非通过mysqldump导入和导出来生成新的库。
页的类型有:
- 数据页(B-Tree Node)
- undo 页(undo log Page)
- 系统页(System Page)
- 事务数据页(Transaction System Page)
- 插入缓冲位图页(Insert Buffer BitMap)
- 插入缓冲空闲列表页(Insert Buffer Free List)
- 未压缩的二进制大对象页(Uncompressed BLOB Page)
- 压缩的二进制大对象页(Compressed BLOB Page)
行
Innodb存储引擎按行进行存放,每个页存放的行记录有影星的定义,最多允许存放16KB/2 - 200 行的记录。
InnoDB行记录格式
Compact 行记录格式
从Mysql5.0开始,设计目的是高效地存储数据。一个页中存放的行数据越多,其性能就越高。
|—|—|—|—|—|—|—|—|—|
| 变长字段长度列表 | NULL标志位 | 记录头信息 | 列1数据 | 列 2 数据 | …|事务ID列|回滚指针列|__rowid|
变长字段长度列表:按照列的顺序,逆序放置。
如果列的长度小于255个字节,占用1字节;
如果列的长度大于255个字节,占用2字节;
变长字段的长度最大不可以超过2个字节,因为Mysql数据库中VARCHAR类型的最大长度限制为65535.
NULL标志位:表示改行数据中是否有NULL值,有用1表示,占用1个字节。
记录头信息:固定占用5个字节。
最后的部分是实际存储没咧的数据。
事务ID列:隐藏列,占用6字节。
回滚指针列:隐藏列,占用7字节。
__rowid:占用6字节。
行溢出数据
InnoDB存储引擎的数据都是存放在页类型为B-tree Node中,当发生行溢出是,数据存放在页类型为uncompress BLOG页中。
InnoDB数据页结构
Named File Formats 机制
###约束
数据完整性
约束的创建和查找
约束和索引的区别
对错误数据的约束
ENUM和SET约束
触发器与约束
外键约束
视图
分区表
分区功能不是在存储引擎层面完成的。
支持分区的存储引擎有:MyISAM、InnoDB、NDB。
不支持分区的存储引擎有:CSV、FEDORATED、MERGE。
分区的过程是将一个表或者索引分解为多个更小的、更可管理的部分。
从逻辑上讲只有一个表或者一个索引库,但是在物理上这个表或者索引可能由数十个物理分区组成。每个分区都是独立的对象,可以独自处理,页可以作为一个更大的对象的一部分进行处理。
Mysql支持水平分区,不支持垂直分区(水平分区,将同一表中的不同行的记录分配到不同的物理文件;垂直分区,将同一表中的不同列分配到不同的物理文件)。
Mysql不支持全局分区,只支持局部分区。
局部分区:一个分区中既存放了数据由存放了索引。
全局分区:数据存放在各个区,所有数据的索引存放在一个对象中。
分区主要用来数据库高可用性的管理,对于某些SQL的性能带来提高。
分区类型
- RANGE分区:行数据基于属于一个给定连续区间的列值被放入分区。
1
2
3
4
5
6
7create table t (
id int
)engine=innodb
partition by range(id)(
partition p0 values less than (10),
partition p1 values less than (20)
);
1 | alter table t add partition (partition p2 values less than maxvalue); |
启用分区后,表是由建立各个分区时的各个分区ibd文件组成。
- List分区:和RANGE分区类似,只是LIST分区面向的是离散的值。
1 | create table t( |
- HASH分区:根据用户自定义的表达式返回值进行分区,返回值不能为负数。
Hash分区的目的是将数据均匀地分布到盂县定义的各个区中,保证各分区的数据数量大致都一样。
1 | create table t( |
1 | create table t( |
LINEAR HASH分区的优点在于,增加、删除、合并和拆分分区将变得更加快捷,有利于处理含有大量数据的表。
缺点在于,与使用HASH分区得到的数据分布相比,各个分区间数据的分布可能不大均衡。
- KEY分区:根据MYSQL数据库提供的哈希函数来分区。
与HASH分区相似,不同之处在于HASH分区使用用户定义的函数进行分区,KEY分区使用MYSQL数据库提供的函数进行分区。对于NDB Cluster引擎,MYSQL数据库使用MD5函数来分区;对于其他引擎,Mysql数据库使用内部的哈希函数。
在KEY分区中,使用关键字LINEAR 和在HASH分区中具有同样的效果。
无论哪种类型的分区,如果表中存在主键或者唯一索引时,分区列必须时唯一索引的一个组成部分。
如果建表时没有指定主键,唯一索引,可以指定任何一个列为分区列。
以上四种RANGE、LIST、HASH、KEY分区条件是,数据必须是整形,如果不是整型,那应该需要通过函数将其转化成整型,如YEAR(), TO_DAYS(), MONTH()等函数。
- Column分区,RANGE分区和LIST分区的一种进化。
COLUMN分区可以直接使用菲整形的数据进行分区,分区根据类型直接比较得到,不需要转化为整形。
RANGECOLUMNS分区可以对多个列的值进行分区。
COLUMN分区支持
所有的整型:INT、SMALLINT、TINYINT、BIGING。
日期类型:DATE、DATETIME
字符串类型:CHAR、VARCHAR、BINARY、VARBINARY。
1 | create table t( |
子分区
子分区是在分区的基础上再进行分区,有时页称为符合分区。 MySQL允许在RANGE和LIST的分区傻姑娘再进行KEY或者HASH的子分区。
1 | create table t( |
分区中的NULL值
MysQL允许对NULL值做分区,对于RANGE分区,如果像分区列插入了NULL值,则Mysql数据库将该值放入到最左边的分区。
LIST分区下要使用NULL值,必须显式地指出将该值放入哪个分区。
HASH和KEY分区函数会将NULL值的记录返回0.
分区和性能
当数据量大时,分区可以有效降低B+树的层级。
当数据量小时,分区带来的收益并不明显,并且有可能导致扫描所有分区反而降低效率。