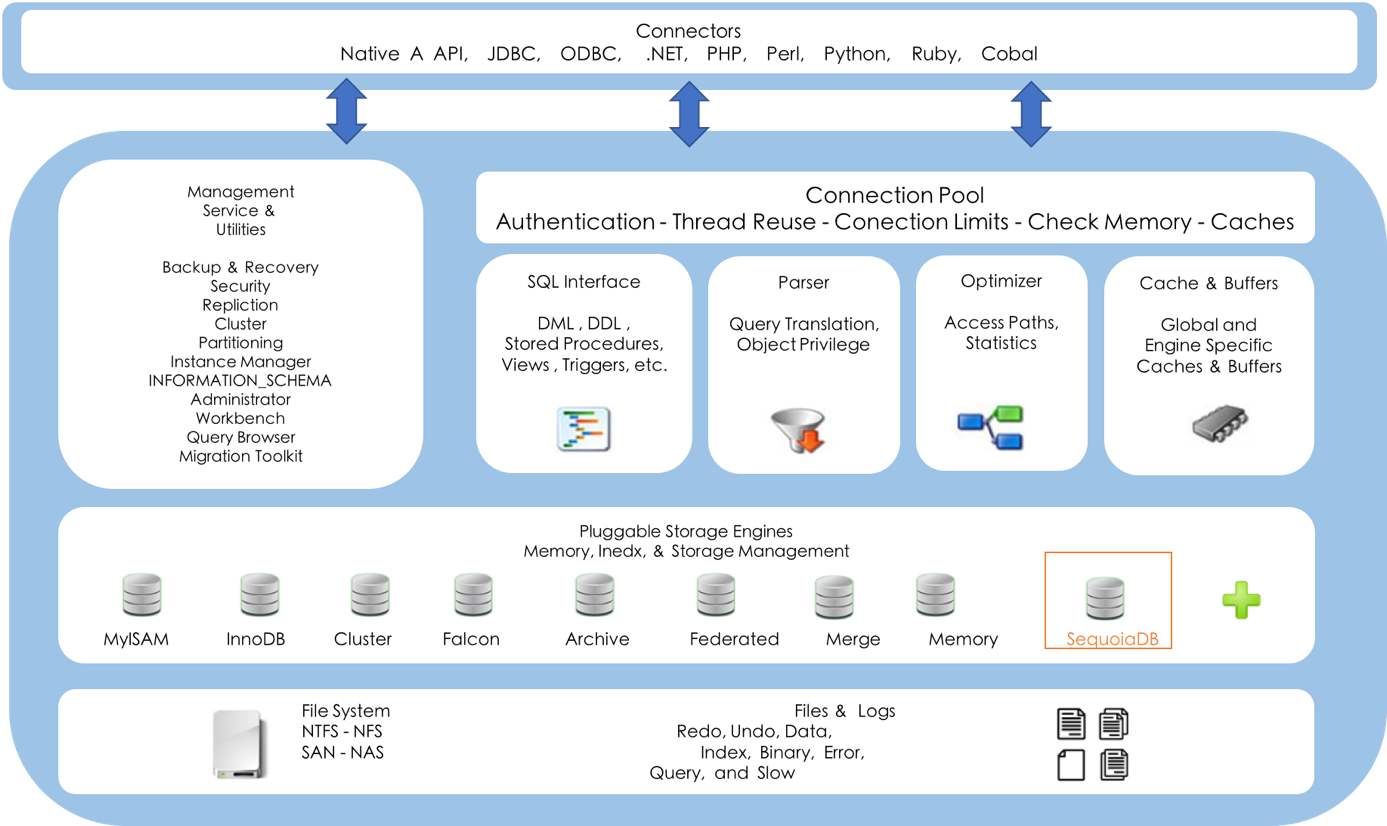
InnoDB 体系架构
后台线程
Master Thread
主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性。
包括脏页的刷新、合并插入缓冲、UNDO页的会后等。
IO Thread
InnoDB中使用了AIO(AsyncIO)来处理写IO请求,提高了数据库性能。
IO线程的工作主要是负责AIO的回调处理。
可以使用innodb_read_io_threads和innodb_write_io_threads进行设置。
Purge Thread
事务被提交后,其所用的undolog可能不再需要,因此需要Perge Thread来回收已经使用并分配的undo页。
可以使用 innodb_purge_thread 来设置线程数量。
Page Cleaner Thread
为了减轻MasterThread的工作,以及用户查询线程的阻塞提升性能。
将之前版本中脏页的舒心操作都放入到单独的线程中完成。
内存
缓冲池
InnoDB存储引擎是基于磁盘存储的,将其中的记录按照页的方式进行管理。缓冲池就是一块内存区域,通过内存的速度来弥补磁盘速度较慢对数据库的性能影响。
在数据库中进行读取页的操作,首先从磁盘读取到的页放在缓冲池中,下一次再读取相同的页时,首先判断该页是否在缓冲池中。如果在缓冲池中,则直接读取该页,否则读取磁盘上的页。
对于数据库中页的修改操作,首先修改在缓冲池中的页,然后再以一定的频率刷新到磁盘上。
页从缓冲池刷新到磁盘上的操作是通过Checkpoint的机制刷新回到磁盘。
因此缓冲池的大小直接影响着数据库的整体性能。可以使用 innodb_buffer_pool_size 来设置缓冲池大小。
缓冲池中缓存的数据页类型有:索引页、数据页、undo页、插入缓冲、自使用哈希索引、InnoDB存储的锁信息、数据字典信息等。
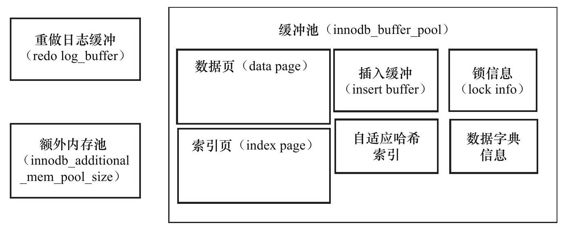
InnoDB可以有多个缓冲池实例,每个页根据哈希值平均分配到不同的缓冲池实例中。这样减少了数据库内部的资源竞争,增加了数据库的兵法处理能力。可以使用 innodb_buffer_pool_instances来进行配置。
缓冲池管理算法
LRU List
LRU List 用来管理已经读取的页,最频繁使用的页存放在LRU列表的前端,最少使用的页存放在LRU列表的尾端。当缓冲池不能存放新读取到的页时,首先释放LRU列表中尾端的页。
新读取的页并不直接存放在LRUList列表的前端,而是存放在midPoint的位置。midPoint之后的列表称为Old列表,之前的列表称为New列表,New列表中的页都是活跃的热点数据。
这是因为,如果新读取的页如果放在最前端时,如果遇到需要访问和扫描大部分甚至全部页的时候,热点页面被刷出缓存,但是非热点数据却存放在了LRU列表的最前端。
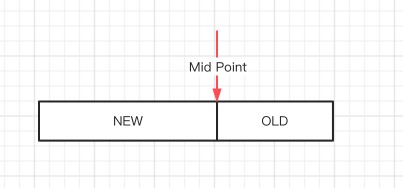
使用参数:innodb_old_blocks_pct 来控制midPoint的位置。
innodb_old_blocks_times 来控制读取到MidPoint位置后需要等待多久才会被加入到LRU列表的New列表。
Free List
数据库刚启动的时候,LRUList是空的没有任何页。此时页都存放在FreeList中。当需要从缓冲中分页时,县从Free列表中查找是否有可用的空闲页,如果有可用的空闲页,则将该页从FreeList中删除,存放到LRUList中。如果FreeList中没有可用的空闲页,根据LRU算法,淘汰LRU尾部的页,将该页内存空间分配给新的页。
Flush List
在LRU列表中的页被修改后,该页需要通过CheckPoint机制刷回磁盘。
FlushList中的页称为脏页里诶包,脏页既存在于LRUList,也存在于FlushList。
LRUList用来管理缓冲池中页的可用性,FlushList用来管理将页刷新回磁盘。
重做缓冲日志
InnoDB存储引擎首先将重做日志信息先放入到这个缓冲区,然后按照一定的频率(每秒一次)将其刷新到重做日志文件。
可以使用参数:innodb_log_buffer_size来调整该缓冲区域的大小,默认为8MB。
额外的内存池
例如:分配了缓冲池(innodb_buffer_pool),但是每个缓冲池中的帧缓冲还有对应的缓冲控制对象,这些对象记录了一些如LRU、锁、等待信息,而这个对象的内存需要从额外内存池中申请。
在对一些数据结构本身的内存进行分配是,需要从额外的内存池中进行申请。因此在申请了很大的InnoDB缓冲池是,需要相应地增加额外的内存池。
Checkpoint技术
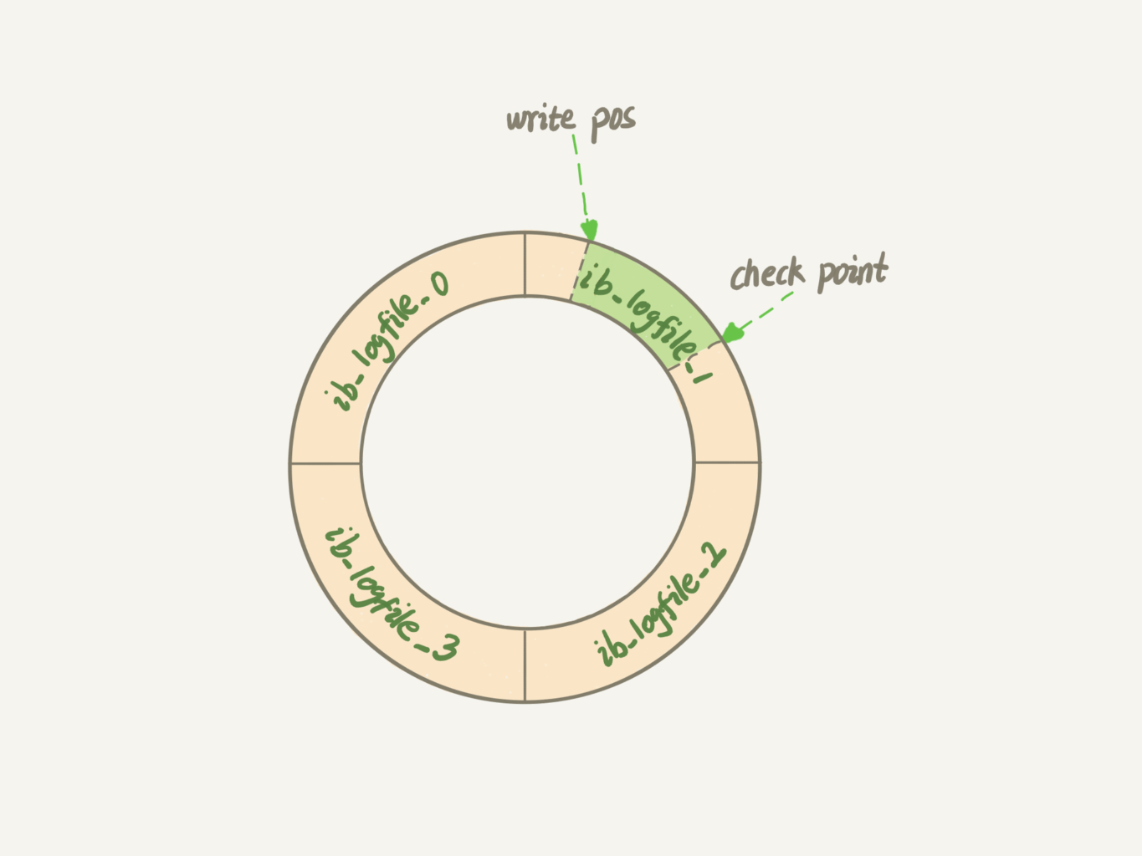
Write Pos 是当前记录的位置,一边写好一遍往后移。
CheckPoint 是当前要擦除的位置,也就是往后推移并且循环的,擦除记录前要把记录更新到数据文件。
Write Pos和 CheckPoint之间是可以写入的部分,用来记录新的操作。
1) 缩短数据库的恢复时间;
当数据库发生宕机时,数据库不需要重做所有的日志,因为CheckPoint之前的页都已经刷新回磁盘,因此只需要对checkPoint之后的重做日志进行恢复,这样大大缩短了数据库的恢复时间。
2) 缓冲池不够用时,将脏页刷新到磁盘;
当缓冲池不够用时,根据LRU算法会移除最近最少使用的页,如果当前页为脏页,则需要刷新该脏页到磁盘。
3) 重做日志不可用时,刷新脏页;
重做日志中Write Pos和checkPint之间没有空间来记录RedoLog时,强制刷新脏页,使得CheckPoint后移。
InnoDB关键特性
插入缓冲
Insert Buffer
对于非聚集索引的插入或者更新操作,不是每一次直接插入到索引页中,而是先判断插入的非聚集索引页是否在缓冲池中,如果存在则直接插入;如果不在则先放入到一个InsertBuffer对象中。然后再以一定的频率进行InsertBuffer和辅助索引页子结点的Merge操作。
通常会将多个插入操作合并到一个操作中,大大提高了非聚集索引插入的性能。
InsertBuffer的使用要同时满足两个条件:
1) 索引是辅助索引(非聚集索引)
如果是聚集索引,则直接按照顺序写就行了,很高效。
2) 索引不是唯一的
因为在插入缓冲时,数据库并不去查找索引页来判断插入的记录唯一性。如果去查找肯定又会有离散读取的情况发生,从而导致InsertBuffer失去意义。
当满足索引是辅助索引且非唯一时,InnoDB存储引擎会使用InsertBuffer, 这样就可以提高插入操作的性能。
当应用程序进行大量的插入操作时数据库发生了宕机,这个时候会有大量的InsertBuffer并没有合并到实际的非聚集索引中,因此恢复可能需要很长的时间。
同时在写密集的情况下,InsertBuffer会占用过多的缓冲池内存(innodb_buffer_pool),默认最大可以占用1/2的缓冲池内存。修改IBUF_POOL_SIZE_PER_MAX_SIZE 可以对 InsertBuffer大小进行控制,比如改为3则最大只能使用1/3的缓冲池内存。
Change Buffer
InsertBuffer 的升级版本,可以对Insert、Delete、Update都进行缓冲,分别是InsertBuffer、DeleteBuffer、PurgeBuffer。
ChangeBuffer适用对象依然是非唯一的辅助索引。
对一条记录进行UPDATE操作需要分为:
1)将记录标记为删除(DeleteBuffer对应该过程);
2)真正将记录删除(PurgeBuffer对应删除操作)
开启Buffer选项:
innodb_change_buffering: [inserts、deletes、purges、changes、all、none]
changes表示启用inserts、deletes
all表示启用所有,默认值
none表示都不启用。
可以通过innodb_change_buffer_max_size控制changebuffer最大使用内存的数量:
该参数的最大有效值为50, 表示只能占用缓冲池的50%。
Merge InsertBuffer
- 辅助索引页被读取到缓冲池时;
执行SELECT语句时,要确认该辅助索引页是否有记录存放于InsertBufferB+树中。
有,则将InsertBufferB+树中该页的记录插入到该辅助索引页中。 - InsertBuffer BitMap 追踪到该辅助索引页已无可用空间时;
InsertBuffer BitMap用来追踪每个辅助索引页的可用空间,并至少有1/32页的可用空间。如果插入辅助索引记录时监测到插入记录后可用空间小雨1/32页,则会强制进行一个合并操作。
(强制读取辅助索引页,将InsertBufferB+树中该页的记录以及待插入的记录插入到辅助索引页中。) - Master Thread
Master Thread 每秒或者每10秒 根据srv_innodb_io_capacity 的百分比来进行一个Merge InsertBuffer操作。
如果在merge时,要进行的merge表已经被删除,此时直接丢弃已经被Insert/Change Buffer的数据记录。
两次写
DoubleWrite为了提升InnoDB存储引擎的数据页可靠性。
当InnoDB存储引擎正在将某个页写入到表中,当这个页只被写了一部分(16k的页,只写了前4k)就发生了宕机,这种情况被称为写失效(partial page write)。
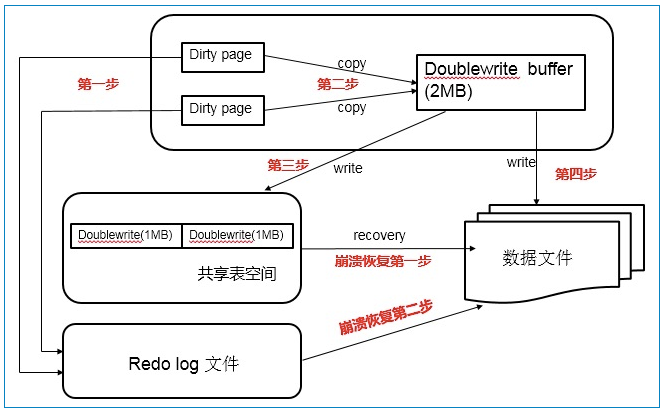
为了解决partial page write,InnoDB实现了Double write buffer,就是在写数据页之前,先把这个数据页写到一块独立的物理文件位置(ibdata),然后再写到数据页。
这样在宕机重启时,如果出现数据页损坏,就需要通过该页的副本来还愿该页,然后再进行redo log重做。
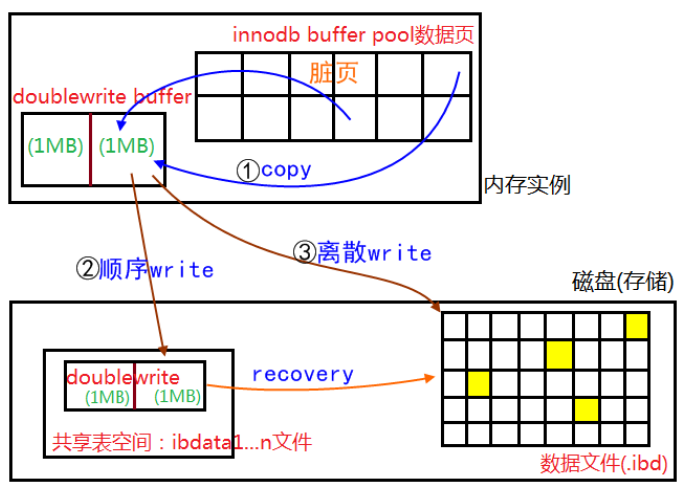
double write由两部分组成,一部分是内存中的double write buffer,大小是2MB, 另一部分是磁盘上的共享表空间中连续的128个页,大小也是2M。
1)当触发数据缓冲池中的脏页刷新时,并不直接写入磁盘数据文件中,而是先拷贝到内存中的doublewrite buffer中;
2)接着从两次写缓冲区分两次写入磁盘共享表空间中(连续存储、顺序写)每次写1MB;
3)再将doublewrite buffer中的脏页数据写入实际的各个表空间中(离散写)。
当不需要开启doublewrite时,使用skip_innodb_doublewrite 关闭。
innodb_buffer_pool_flushed : 当前从缓冲池中刷新到磁盘页的数量
innodb_dblwr_pages_written: double write 的数量
自适应哈希索引
InnoDB存储引擎会监控对标上各索引页的查询,如果观察到建立哈希索引可以带来速度上的提升,则建立哈希索引。自适应哈希索引是通过缓冲池的B+树页构造而来,因此建立的速度很快,不需要对整张表建立哈希索引。 InnoDB存储引擎会自动根据访问的频率和模式来自动地为某些热点页建立哈希索引。
自使用哈希索引有一个要求,对这个页的查询条件是一样的。
如:where a = xxx;
where a = xxx and b = xxx;
自使用哈希索引是数据库自优化的,无需DBA对数据库进行调整。
可以通过innodb_adaptive_hash_index 来启用或者禁用。
异步IO
1)提升吞吐量
2)IO Merge操作
刷新邻接页
当刷新一个脏页时,InnoDB存储引擎会检测该页所在区的所有页,如果是脏页,那么一起进行刷新。
通过AIO可以将多个IO卸乳操作合并为一个IO操作。
可以通过innodb_flush_neighbors 来关闭或者开启该特性。
select version();
show variables like ‘innodb_%_threads’;
show variables like ‘innodb_buffer_pool_size’;
show variables like ‘innodb_buffer_pool_instances’;
show variables like ‘innodb_change_buffering’;
show engine innodb status;