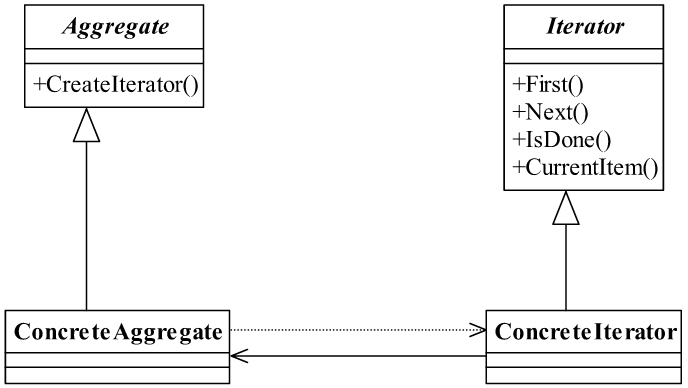
解释器模式 解释器模式是一种按照规定语法进行解析的方案。
定义 给一门语言,定义它的文法的一种表示,并且定义一个解释器,该解释器使用该表示来解释语言中的句子。
比如Java语言,定义文法的表示是Java的语法。
实现 AbstractExpression 抽象解释器,抽象解释器通常只有一个方法, 是生成语法集合的关键,每个语法集合完成指定语法的解析任务,通过递归调用的方式,最终由最小的语法但愿进行解析完成。
1 2 3 4 5 6 7 8 9 10 11 public abstract class Expression public abstract int interpreter (HashMap<String,Integer> var ) }
TerminalExpression 终结符表达式
1 2 3 4 5 6 7 8 9 10 11 12 13 public class VarExpression extends Expression private String key; public VarExpression (String key) this .key = key; } @Override public int interpreter (HashMap<String, Integer> var ) return var .get(this .key); } }
NoneTerminalExpression 非终结符表达式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public abstract class SymbolExpression extends Expression protected Expression left; protected Expression right; public SymbolExpression (Expression left, Expression right) this .left = left; this .right = right; } } public class AddExpression extends SymbolExpression public AddExpression (Expression left, Expression right) super (left, right); } @Override public int interpreter (HashMap<String, Integer> var ) return super .left.interpreter(var ) + super .right.interpreter(var ); } } public class SubExpression extends SymbolExpression public SubExpression (Expression left, Expression right) super (left, right); } @Override public int interpreter (HashMap<String, Integer> var ) return super .left.interpreter(var ) - super .right.interpreter(var ); } }
Context 环境角色,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class Calculator private Expression expression; public Calculator (String expStr) Stack<Expression> stack = new Stack<>(); char [] charArray = expStr.toCharArray(); Expression left = null ; Expression right = null ; for (int i = 0 ; i < charArray.length; i++) { switch (charArray[i]) { case '+' : left = stack.pop(); right = new VarExpression(String.valueOf(charArray[++i])); stack.push(new AddExpression(left, right)); break ; case '-' : left = stack.pop(); right = new VarExpression(String.valueOf(charArray[++i])); stack.push(new SubExpression(left, right)); break ; default : stack.push(new VarExpression(String.valueOf(charArray[i]))); break ; } } this .expression = stack.pop(); } public int run (HashMap<String, Integer> var ) return this .expression.interpreter(var ); } }
Use 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public static void main (String[] args) throws IOException String expStr = getExpStr(); HashMap<String, Integer> var = getValue(expStr); Calculator calculator = new Calculator(expStr); System.out.println(calculator.run(var )); } private static HashMap<String, Integer> getValue (String expStr) throws IOException HashMap<String, Integer> map = new HashMap<>(); for (char c : expStr.toCharArray()) { if (c != '+' & c != '-' ) { if (!map.containsKey(String.valueOf(c))) { String in = (new BufferedReader(new InputStreamReader(System.in))).readLine(); map.put(String.valueOf(c), Integer.valueOf(in)); } } } return map; } private static String getExpStr () throws IOException System.out.println("Input Expression" ); return new BufferedReader(new InputStreamReader(System.in)).readLine(); }
应用 优点 扩展性良好,修改语法规则只需要修改相应的非终结符表达式就可以了。
缺点 解释器模式会引起类膨胀,每个语法都要产生一个非终结符表达式,语法规则比较复杂时,就可以能产生大量的类文件。
效率问题,解释器模式使用大量的循环和递归,效率时一个很大的问题。
使用场景 重复发生的问题可以解释器模式,多个应用服务器,每天产生大量的日志,需要对日志文件进行分析处理,由于各个服务器的日志格式不同,但是数据要素相同,按照解释器模式终结符表达式相同,非终结符表达式需要定制。
一个简单语法需要解释的场景,解释器模式一般用来解析表标准的字符集,如SQL语法分析。
注意事项 尽量不要在重要的模块中使用解释器模式,维护成本太高。尽量使用shell、JRuby、Groovy来替代。
扩展 成熟的工具